
Atomic vs Non-Atomic 연산
원문 : http://preshing.com/20130618/atomic-vs-non-atomic-operations/
단시간의 지식 습득을 위해 빠른 속도로 번역을 한 것이기 때문에 자연스럽지 못한 문구들이 많이 있을 수 있다.
애매한 문구에 연연하기 보다는 핵심적인 내용만 파악하면 될 것이다. 아래 글을 읽고도 의미가 명확하지 않은 문구들에 대해서는 원문을 읽어보기를 바란다.
Atomic vs. Non-Atomic Operations
Web 상에 atomic 연산들에 대해 이미 많은 글들이 올라와있다.
이러한 글들은 대부분 atomic read-modify-write(RMW) 연산들에 초점이 맞추어져 있다.
그러나, 그것들이 유일한 atomic 연산은 아니다.
마찬가지로 중요한 atomic store 와 load 들도 있다.
이 포스팅에서는 atomic load 와 store 들을 non-atomic 한 것들과 processor level 에서, 그리고 C/C++ language level 에서 비교해볼 것이다. 그 과정에서, 우리는 C++11 의 "data race" 의 개념을 명확히 하게 될 것이다.
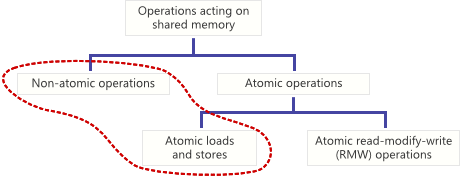
공유메모리상에서 동작하는 연산이 만약 다른 스레드들과 경쟁하여 single step 안에서 완료한다면 이를 atomic 하다고 할 수 있다. 공유변수에 대해 atomic store 가 실행될 때, 다른 스레드가 그 변경이 완료되지 않은 상태를 볼 수 있다. 공유변수에 대해 atomic load 가 실행될 때, 이는 어느 한 순간에 나타난 것처럼 전체값을 읽어버린다. Non-atomic load 와 store 는 이런 상황들을 보장해주지 않는다.
이러한 보장이 없으면, lock-free 프로그래밍이 불가능할 것이다.
왜냐하면, 다른 스레드가 공유변수를 절대 같은 순간에 조작하도록 허용하지 않을 것이니 말이다.
우리는 이를 하나의 룰로서 공식화할 수 있다.
"두개의 스레드가 동시에 공유변수에 대해 연산을 하고, 그 연산들 중의 하나는 write 를 수행할 때는, 양쪽 스레드는 반드시 둘다 atomic 연산을 사용해야 한다."
만약 이러한 rule 을 어기고 어느 스레드라도 non-atomic 연산을 사용한다면, 여러분은 C++11 표준에서 얘기하는 "data race"상황을 맞을 것이다. (자바에서 말하는 data race, 그리고 일반적으로 말하는 race condition 과 혼동하지 말라)
C++11 표준은 data race 가 왜 나쁜지 말하지는 않고, 단지 data race 상황을 만나면 예기치 못한 동작(undefined behavior)이 발생할 수 있다고 말한다.
data race 가 나쁜 진짜 이유는 사실 간단하다.
그것이 갈라진 read 와 write(torn read and write)의 결과로 나타난다는 점이다.
메모리 연산은 다수의 CPU 명령들을 사용하기 때문에 non-atomic 일 수 있다.
하나의 CPU 명령을 사용할 때 조차도 non-atomic 일 수 있고, 또는 이식가능한 코드를 작성하여 어떻게 동작할지 추측할 수 없을 때도 non-atomic 일 수 있다.
몇가지 예를 보자.
Non-Atomic Due to Multiple CPU Instructions
0 으로 초기화된 64 비트 전역변수가 있다고 하자.
uint64_t sharedValue = 0;
어느 시점에서 이 변수에 64 비트 값을 할당한다.
void storeValue()
{
sharedValue = 0x100000002;
}
이 함수를 GCC를 이용하여 32 비트 x86 용으로 컴파일하면, 다음과 같은 기계어를 만들어낸다.
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov DWORD PTR sharedValue, 2
mov DWORD PTR sharedValue+4, 1
ret
...
위에서 보듯이, 컴파일러는 64 비트 할당작업을 두개의 별도 명령어를 이용하여 처리하였다.
첫번째 명령은 하위 32 비트를 0x00000002 로 설정하고, 두번째 명령은 상위 32 비트를 0x00000001 로 설정하였다.
분명히 이 할당 작업은 atomic 하지 않다.
만약 sharedValue 가 다른 스레드들에 의해 동시에 접근된다면 다음과 같이 몇가지가 잘못될 수 있다.
- 만약 storeValue 를 호출한 스레드가 두 명령어 사이에 선점당한다면, 메모리에는 0x0000000000000002 값이 남아있는 갈라진 write (torn write) 상태가 될 것이다. 이 시점에서 다른 스레드가 sharedValue 를 읽으면, 이는 아무도 의도하지 않은 완전히 잘못된 값을 얻게 될 것이다.
- 더욱 심각한 것은, 한 스레드가 두개의 명령어 사이에 선점당하고, 다른 스레드가 sharedValue 값을 첫번째 스레드가 재수행되기 전에 변경한다면 영원한 torn write 결과를 낳을 것이다. 즉, 한 스레드에 의해 상위 32 비트가, 다른 스레드에 의해 하위 32 비트가 쓰여지는 결과 말이다.
- 멀티코어 시스템에서는, ...
하나의 스레드가 storeValue 를 호출할 때, 다른 코어에서 실행되는 스레드가 위처럼 반만 변경된 시점에 sharedValue 를 읽을 수 있다.
sharedValue 를 동시에 읽는 것은, 일련의 문제들을 야기한다.
uint64_t loadValue()
{
return sharedValue;
}
$ gcc -O2 -S -masm=intel test.c
$ cat test.s
...
mov eax, DWORD PTR sharedValue
mov edx, DWORD PTR sharedValue+4
ret
...
또한 위의 예를 보면, 컴파일러가 load 연산을 하기 위해 두개의 명령을 사용하였다.
첫번째는 하위 32 비트를 eax 로 읽어들이고, 두번째는 상위 32 비트를 edx 로 읽어들인다.
이 경우에는, sharedValue 에 동시에 store 하는 것은 두개의 명령 사이에서 visible 하게 된다.
즉, concurrent store 가 atomic 하다고 하더라도 torn read 를 발생시킨다.
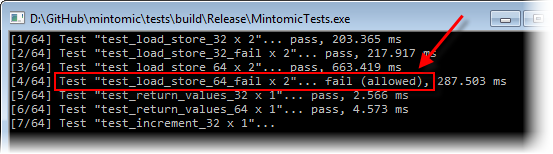
이런 문제들은 단지 이론적인 것이 아니다. Minitomic 의 test suite 는 test_load_store_64_fail 이라는 test case 를 포함한다.
하나의 스레드가 64 비트 값들을 하나의 변수에 마구마구 할당하고, 다른 스레드는 같은 변수로부터 load 를 수행한다.
예상한대로 멀티코어 x86 환경에서 이 테스트는 지속적으로 실패한다.
Non-Atomic CPU Instructions
하나의 CPU 명령에 의해 메모리 연산이 수행될 때 조차도 non-atomic 일 수 있다.
예를 들면, ARMv7 의 명령어셋에 strd 라는 명령어가 있는데, 이는 두개의 32 비트 소스 레지스터의 내용을 메모리에 있는 하나의 64 비트 값으로 저장한다.
strd r0, r1, [r2]
일부 ARMv7 프로세서에서는 이 명령이 atomic 하지 않다.
프로세서가 이 명령을 만나면, 실제적으로는 2 개의 분리된 32 비트 store 로 처리한다.
다시 말하지만, 다른 코어에서 수행중인 스레드는 torn write 를 볼 가능성을 가진다.
흥미롭게도, torn write 는 단일코어 시스템에서도 가능하다.
시스템 인터럽트(스케줄링에 의한 컨텍스트 스위치)가 두개의 내부적인 32 비트 store 사이에 발생할 수 있다.
이런 경우에는, 스레드가 인터럽트로부터 돌아와 다시 재수행될 때는 strd 명령을 처음부터 완전히 다시 시작할 것이다.
또다른 예로, x86 에서는 잘 알려져있는데, 32 비트 mov 연산은 만약 메모리 operand 가 align 되어 있다면 atomic 하다.
하지만, align 되어 있지 않다면 atomic 하지 않다.
다른 말로 하면, 32 비트 integer 가 정확히 4 의 배수 주소에 위치하고 있을 때만이 atomic 하다고 할 수 있다.
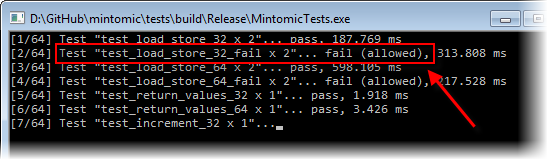
Mintomic 의 또다른 테스트, test_load_store_32_fail 은 이를 확인시켜준다.
위에 기록한대로 하면, 이 테스트는 x86 에서 항상 성공한다.
하지만, sharedInt 를 강제로 align 되지 않은 특정 주소로 변경하면 테스트는 실패한다.
내 Core 2 Quad Q6600 환경에서, 테스트는 sharedInt 가 cache line 의 경계를 넘어갈 경우 실패한다.
// Force sharedInt to cross a cache line boundary:
#pragma pack(2)
MINT_DECL_ALIGNED(static struct, 64)
{
char padding[62];
mint_atomic32_t sharedInt;
}
g_wrapper;
All C/C++ Operations Are Presumed Non-Atomic
C 와 C++ 에서는 만약 컴파일러나 하드웨어 벤더에 의해 특별히 명기되지 않는 한, 모든 연산은 non-atomic 한 것으로 가정한다. 일반적인 32 비트 integer 할당작업조차도 말이다.
uint32_t foo = 0;
void storeFoo()
{
foo = 0x80286;
}
언어의 표준은 위와 같은 경우에 대해 atomicity 관련 어떤 언급도 없다.
어쩌면 integer 할당작업은 atomic 할 것이고, 어쩌면 atomic 하지 않을 것이다.
non-atomic 연산들은 어떤 보장도 하지 않기 때문에, C 에서의 일반적인 integer 할당은 non-atomic 하다. (?)
실제로, 우리는 일반적으로 우리의 타겟 플랫폼에 대해 더 많이 알고 있다.
예를 들면, 모든 현대의 x86, x64, Itanium, SPARC, ARM and PowerPC 프로세서에서 변수가 align 되어 있는 한 integer 할당 작업은 atomic 하다는 것이 일반적인 상식이다.
여러분은 프로세서 매뉴얼이나 컴파일러 문서를 통해 그를 증명할 수 있다.
게임 산업에서는, 많은 32 비트 할당이 이러한 특정 보증에 달려있다고 말할 수 있다.
그럼에도 불구하고, 이식가능한 C 와 C++ 을 작성할 때, 언어의 표준이 말해주는 것 이상을 우리는 알지 못하는 척하는 오랜 전통이 있다. 이식가능한 C 와 C++ 은 과거, 현재, 상상의 모든 종류의 컴퓨팅 장비에서 작동하도록 설계된다.
개인적으로는 맨먼저 마구 섞어버린 상태에서만 메모리가 갱신될 수 있는 장비를 상상하고 싶다.

그런 장비에서는, 여러분은 값의 할당과 동시에 read 를 수행하는 것을 원하지 않을 것이다.
결국 여러분은 완전히 random 수를 읽을 것이다.
C++11 에서는, 진정으로 이식가능한 atomic load 와 store 를 수행하는 방법이 있다. C++11 atomic library 이다.
C++11 atomic library 를 이용하여 수행되는 atomic load 와 store 는 위에서 보았던 상상의 컴퓨터에서조차 동작할 것이다.
비록 그것이 C++11 atomic library 가 비밀스럽게 각각의 연산을 atomic 하게 만들기 위해 mutex lock 을 이용해야한다는 것을 의미한다고 해도 말이다.
지난 달에 릴리즈한 Mintomic library 가 있는데, 그리 많은 플랫폼을 지원하지는 않지만, 몇몇의 예전 컴파일러에서 동작하고, 직접 최적화했으며 lock-free 를 보장한다.
Relaxed Atomic Operations
이 포스팅의 초기에 보여주었던 sharedValue 예로 돌아가보자.
모든 연산이 Mintomic 이 지원하는 모든 플랫폼에서 atomic 하게 수행되도록 Mintomic 을 이용해서 다시 써볼 것이다.
첫째로, Mintomic 의 atomic data type 으로 sharedValue 를 선언해야 한다.
#include <mintomic/mintomic.h>
mint_atomic64_t sharedValue = { 0 };
mint_atomic64_t 타입은 각각의 플랫폼에서 atomic 접근을 위해 정확한 메모리 alignment 를 보장한다.
이는 중요하다.
예를 들면, Xcode 3.2.5 와 번들로 나오는 GCC 4.2 컴파일러는 uint64_t 이 8 바이트 align 된 것을 보장하지 않는다.
storeValue 에서 단순히 non-atomic 한 할당을 사용하는 대신, mint_store_64_relaxed 를 호출해야 한다.
void storeValue()
{
mint_store_64_relaxed(&sharedValue, 0x100000002);
}
유사하게, loadValue 에서는 mint_load_64_relaxed 를 호출한다.
uint64_t loadValue()
{
return mint_load_64_relaxed(&sharedValue);
}
C++11 용어를 이용해서 말하면, 이러한 기능은 이제 data race free 한 것이다.
동시에 수행될 때, torn read 나 torn write 가 발생할 가능성은 없다. (ARMv6/ARMv7, x86, x64, PowerPC 환경에서)
만약 mint_load_64_relaxed 와 mint_store_64_relaxed 가 실제로 어떻게 동작하는지 궁금하다면, x86 에서는 두 함수 모두 inline cmpxchg8b 명령어를 이용한다는 것을 알아두라.
다른 플랫폼에 대해서는 Mintomic 의 implemention 을 참조해라.
아래는 C++11 로 대신 쓰여진 정확히 동일한 것을 보여준다.
#include <atomic>
std::atomic<uint64_t> sharedValue(0);
void storeValue()
{
sharedValue.store(0x100000002, std::memory_order_relaxed);
}
uint64_t loadValue()
{
return sharedValue.load(std::memory_order_relaxed);
}
구현 코드 : 구현코드는 여기
