
Memory Access Ordering(2) – barriers and the Linux Kernel
The Original(원문) : barriers and the Linux Kernel
Linux Kernel 에 구현된 실제 코드를 바탕으로 barrier 를 아래와 같이 분류하여 잘 설명되어 있는 포스팅을 번역해 보았다. barrier 에 대해 개념을 잡고 싶다면 꼭 읽어보기를 바란다.
- General barrier(컴파일러 배리어)
- Mandatory barrier(시스템 차원의 메모리 배리어)
- SMP 전용 barrier
- 암시적 barrier
- 기타 barrier
My previous post provided an introduction to the concept of memory access ordering. It did not however provide any solution to the problem, or necessarily specify where such ordering can be significant.
Now, not all software developers need to be deeply aware of memory access ordering or barriers. Unless your code interacts directly with hardware, interacts directly with code executing on other cores or directly loads or generates instructions to be executed, things will mostly Just Work. If your interaction with hardware is completely through a device driver (meaning: no device control registers mapped directly into your application), then it is the responsibility of the driver to enforce ordering. If your communication with software running on a different core makes use of a multithreading API, for example using Pthreads or Java threads, then it is the responsibility of that API to enforce ordering. If your program executes on an operating system that implements demand paging, then clearly it is the responsibility of the operating system to enforce ordering of such operations.
However, if you are writing device drivers, implementing your own thread-communications or creating a JIT compiler, then not being aware of the proper use of barriers can lead to unexpected and difficult to diagnose problems. Where your program requires a specific order of memory accesses to be seen by multiple cores or devices in the system, the solution is called barriers.
While the underlying architectural concepts are interesting in themselves, they are not what the majority of software developers concerned with barriers need to know about. For that reason, this post covers barrier use within the Linux kernel only. I promise to return to the gritty detail in a later post.
내 이전 포스팅에서 memory access ordering 의 개념에 대한 소개를 했다. 그렇지만, 그것은 문제들에 대해 어떤 해결책도 제시하지 않았고, 그러한 ordering 이 언제 중요한지도 구체적으로 언급하지 않았다.
모든 소프트웨어 개발자가 memory access odering 이나 barrier 에 대해 깊이있게 알 필요는 없다.
여러분의 코드가 하드웨어와 직접적으로 상호작용하지 않는다면, 또한 다른 코어에서 실행되는 코드와 직접적으로 상호작용하지 않는다면, 그리고 실행될 명령들을 직접 load 하고 생성하는 것이 아니라면, 대부분 모든게 잘 동작하게 되어 있다.
만약 여러분이 디바이스 드라이버를 통해 하드웨어와 상호작용한다면(즉, 당신의 프로그램과 디바이스 제어 레지스터가 직접 매핑되지 않는다면), 그것은 ordering 을 조정하는 것은 드라이버의 책임이다.
만약 다른 코어에서 실행되는 소프트웨어와의 통신이 pthread 나 java thread 같은 멀티스레드 API 를 이용한다면, ordering 을 조정하는 것은 API 의 책임이다.
demand paging 을 사용하는 OS 상에서 여러분의 프로그램이 실행된다면, 분명히 그러한 연산들의 ordering 을 조정할 책임은 OS 에 있다.
하지만, 여러분이 디바이스 드라이버를 작성하거나, 스레드 통신을 직접 구현하거나, JIT 컴파일러를 만들거나 한다면, barrier 에 대해 알지 못하는 것이 예측못한 문제를 일으킬 수 있고 이 문제를 진단하는데도 어려움을 겪게 된다.
여러분의 프로그램이 멀티코어나 디바이스들에 의해 일정한 순서의 메모리 접근이 요구된다면, 그 해답이 barrier 라고 불린다.
기저의 아키텍쳐 개념 그 자체는 흥미롭지만, 대부분의 소프트웨어 개발자들이 관심있고 알아야하는 barrier 와 관련된 내용은 아니다. 이런 이유로, 이 포스팅에서는 Linux Kernel 에서 사용하는 barrier 에 대해서만 다루도록 한다.
나중에 더 상세한 내용의 포스팅으로 돌아올 것을 약속한다.
So, what are these barriers then?
A barrier, in some architectures called a fence, is an operation that explicitly enforces some type of ordering of memory accesses. On the higher level this can mean compiler directives preventing load/store operations from being reordered across a line in the source code, but leaving the compiler free to rearrange memory accesses on either side with other accesses on the same side. On the lower level, this can mean dedicated instructions stopping execution on a core until all previous memory accesses are guaranteed to be visible to other agents in the system. An agent is any device in the system capable of initiating bus transactions - for example a processor or a DMA controller.
Figure 1 shows an example of a barrier affecting the ordering of load-store instructions.
Fugure 1.
There is an ordering dependency that the effects of Store 1 are visible to Load 2. For example, Store 1 might be a write to a configuration register that remaps the physical address of a peripheral that is then read from by Load 2. Note that accesses on either side of the barrier can still be freely reordered where there are no address dependencies.
barrier(어떤 아키텍쳐에서는 fence 라고 불림)는 메모리 접근에 대한 ordering 을 명시적으로 강제하는 명령이다.
상위 레벨에서 얘기하면, 이러한 barrier 라는 것이 load/store 명령이 소스코드의 barrier 가 기록된 라인을 넘나들어서 재배치(reorder)되는 것을 막아주는 컴파일러 directive 를 의미할 수 있다. 하지만, 이는 컴파일러가 barrier 라인의 양쪽에서 같은 쪽의 다른 명령어들과 재배치되는 것까지 막지는 못한다.
하위 레벨에서 얘기하면, 모든 앞선 메모리 접근들이 시스템의 다른 agent 들에게 visible 하다는 것을 보장할 때까지 하나의 코어에서의 실행을 멈추는 전용 명령어를 의미할 수 있다.
Agent 는 시스템에서 bus transaction 을 개시할 수 있는 어떤 종류의 디바이스도 포함된다. 예를 들면, 프로세서라든가 DMA 컨트롤러도 포함된다.
그림 1 은 load/store 명령의 순서에 영향을 미칠 수 있는 barrier 의 예를 보여준다.
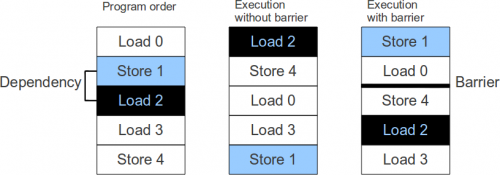
Store 1 의 결과가 Load 2 에게 visible 해야하는 의존성이 존재한다. 예를 들면, Store1 은 configuration 레지스터에 써서 주변장치의 물리주소를 remap 시키고, 이는 Load2 에 의해 읽혀진다.
barrier 의 양쪽 side 에서의 메모리 접근은 의존성만 없으면 자유롭게 재배치될 수 있다는 것을 기억하라.
Barriers in the Linux kernel
Because the compiler directives, barrier instructions and other system operations will differ between vendors, architectures and overall set of system components, the Linux kernel defines a portable set of barrier operations that need to be implemented for each architecture. Since the supported architecture with the weakest memory model (effectively the one that permits the most reordering) was the DEC Alpha, this was used as the reference architecture. No other architectures have since surpassed the DEC Alpha in this regard, but ARMv7-A comes pretty close. The full documentation of the barriers available in the Linux kernel can be found in linux/Documentation/memory-barriers.txt, but I will give a quick intro here.
컴파일러 directive 나 barrier 명령, 다른 시스템 연산들이 벤더나 아키텍쳐마다 다를 것이기 때문에, Linux Kernel 은 각각의 아키텍쳐에 적용가능하도록 포팅가능한 일련의 barrier 명령들을 정의하고 있다.
지원하는 아키텍쳐 중 DEC Alpha 가 가장 weakest 한 메모리 모델(대부분의 reordering 을 허용)을 사용하기 때문에, 이 아키텍쳐가 레퍼런스 아키텍쳐로서 사용된다.
어떤 아키텍쳐도 이 부분에서 DEC Alpha 를 넘어선 적이 없지만, ARMv7-A 가 거의 근접해있다.
linux/Documentation/memory-barriers.txt 를 보면 가용한 barrier 에 대한 모든 것이 나와 있지만, 여기에서는 빠르게 소개를 하는 것으로 하겠다.
Linux barrier API
General barrier
A general barrier has no runtime effect, it is only an instruction to the compiler to prevent reordering of memory accesses for optimization purposes.
Statement : barrier()
Description : Compiler barrier only. The compiler will not reorder memory accesses from one side of this statement to the other. This has no effect on the order that the processor actually executes the generated instructions.
general barrier 는 runtime 에는 영향을 주지 않는다. 이는 컴파일러가 최적화를 위해 수행하는 메모리 접근의 reordering 을 막아주는 명령어일 뿐이다.
명령어 : barrier()
설명 : 단지 컴파일러 barrier 이다. 컴파일러는 barrier 의 양쪽을 넘나들며 reordering 을 하지 않는다. 이는 프로세서가 생성된 명령어들을 실행할 때의 순서에는 영향을 주지 못한다.
Mandatory barriers
Mandatory barriers are used to enforce memory consistency on a full system level. The most common example of this is when communicating with external memory mapped peripherals. All mandatory barriers are guaranteed to expand to at least a compiler barrier, regardless of target architecture.
Statement : mb()
Description : A full system memory barrier. All memory operations before the mb() in the instruction stream will be committed before any operations after the mb() are committed. This ordering will be visible to all bus masters in the system. It will also ensure the order in which accesses from a single processor reaches slave devices.
Statement : rmb()
Description : Like mb(), but only guarantees ordering between read accesses. That is, all read operations before an rmb() will be committed before any read operations after the rmb().
Statement : wmb()
Description : Like mb(), but only guarantees ordering between write accesses. That is, all write operations before a wmb() will be committed before any write operations after the wmb().
Mandatory barrier 는 전체 시스템 레벨에서 메모리 정합성을 강제하는데 사용된다. 이의 가장 일반적인 예는 mamory mapped 주변장치와 통신하는 경우이다.
모든 mandatory barrier 는 아키텍쳐에 상관없이 적어도 컴파일러 barrier 의 역할까지의 확장은 보장한다.
명령어 : mb()
설명 : full system memory barrier. 명령어 스트림에서 mb() 이전의 모든 메모리 연산들은 mb() 이후의 연산들이 커밋되기 전에 모두 커밋된다. 이러한 순서는 시스템의 모든 버스 마스터에게 visible 하게 된다. 또한, 단일 프로세서로부터의 메모리 접근 순서가 slave 디바이스에 도달하는 순서와 같도록 보장해준다.
명령어 : rmb()
설명 : mb()와 비슷하지만, 읽기 접근들 사이의 ordering 만 보장한다는 것이 다르다. 즉, rmb() 이전의 모든 읽기 연산이 rmb() 이후의 연산 이전에 커밋된다.
명령어 : wmb()
설명 : mb()와 비슷하지만, 쓰기 접근들 사이의 ordering 만 보장한다는 것이 다르다. 즉, wmb() 이전의 모든 쓰기 연산이 wmb() 이후의 연산 이전에 커밋된다.
SMP conditional barriers
The SMP conditional barriers are used to ensure a consistent view of memory between different cores within a cache coherent SMP system. When compiling a kernel without CONFIG_SMP, all SMP barriers are converted into plain compiler barriers.
Note: SMP barriers are a subset of mandatory barriers, not a superset (which is a common misunderstanding). An SMP barrier cannot replace a mandatory barrier, but a mandatory barrier can replace an SMP barrier.
Statement : smp_mb()
Description : Similar to mb(), but only guarantees ordering between cores/processors within an SMP system. All memory accesses before the smp_mb() will be visible to all cores within the SMP system before any accesses after the smp_mb().
Statement : smp_rmb()
Description : Like smp_mb(), but only guarantees ordering between read accesses.
Statement : smp_wmb()
Description : Like smp_mb(), but only guarantees ordering between write accesses.
SMP 전용 barrier 는 캐쉬 일관성을 지키는 SMP 시스템내에서 서로 다른 코어들 사이의 메모리 정합성을 보장하기 위해 사용된다. 커널을 CONFIG_SMP 없이 컴파일하면, 모든 SMP barrier 는 일반적인 컴파일러 barrier 로 변환된다.
Note: SMP barrier 는 mandatory barrier 의 하위 개념이다. 잘못 이해되는 경우가 많은데 상위 개념이 아니다. SMP barrier 가 madatory barrier 를 대체할 수는 없지만, mandatory barrier 가 SMP barrier 를 대체할 수는 있다.
Statement : smp_mb()
Description : mb()와 유사하지만, SMP 시스템에서만 코어/프로세서 사이의 ordering 을 보장한다. smp_mb() 이전의 모든 메모리 접근은 smp_mb() 이후의 어떤 접근이전에 SMP 시스템 내의 모든 코어들에게 visible 하다.
Statement : smp_rmb()
Description : smp_mb()와 유사하지만, 읽기 접근 사이의 ordering 만을 보장한다.
Statement : smp_wmb()
Description : smp_mb()와 유사하지만, 쓰기 접근 사이의 ordering 만을 보장한다.
Implicit barriers
Locking constructs available within the kernel act as implicit SMP barriers, in the same way as pthread synchronization operations do in user space. When using these to protect a shared resource, explicit barriers need not be used as well (for the purpose of ensuring consistency of that resource). This does not however remove the need for explicit barriers when communicating with external masters.
Due to a large number of device drivers not using the required barriers, I/O accessor macros (readb(), iowrite32() etcetera) for the ARM architecture act as explicit memory barriers when the kernel is compiled with CONFIG_ARM_DMA_MEM_BUFFERABLE. This was added in linux-2.6.35.
커널내의 Locking 구조들도 implicit SMP barrier 로서 동작한다. pthread 동기화 연산들도 사용자 영역에서는 같은 방식으로 동작한다. 공유자원을 보호하기 위해 이러한 것들을 사용하면, 그 리소스의 정합성을 보장하기 위한 목적으로 사용되는 명시적인 barrier 는 불필요하게 된다.
하지만, 이것이 외부 마스터와의 통신 시에도 명시적인 barrier 를 불필요하게 만드는 것은 아니다.
필요한 상황에서도 barrier 를 사용하지 않는 많은 디바이스 드라이버때문에, ARM 아키텍쳐용 I/O 접근 매크로(readb(), iowrite32() 등)는 커널이 CONFIG_ARM_DMA_MEM_BUFFERABLE 설정으로 컴파일되었을 때 명시적인 메모리 barrier 로 동작한다. 이것은 linux-2.6.35 에서 추가되었다.
Other barriers
There are other barriers available within the Linux kernel as well. This post covered only the most commonly required ones. Please see the Linux kernel documentation for more information.
Linux Kernel 에는 가용한 다른 barrier 들도 있다. 이 포스팅에서는 주로 많이 사용되는 것들에 대해서만 다루었다.
더 많은 정보는 Linux Kernel 문서를 참조하라.
Usage Examples
The Linux kernel patch submission guidelines state that "All memory barriers {e.g., barrier(), rmb(), wmb()} need a comment in the source code that explains the logic of what they are doing and why.". Although this is not always adhered to, this means that the kernel source itself can be a useful reference for the use of barriers. For example, the following is taken from linux/drivers/net/8139too.c:
/*
* Writing to TxStatus triggers a DMA transfer of the data
* copied to tp->tx_buf[entry] above. Use a memory barrier
* to make sure that the device sees the updated data.
*/
wmb();
RTL_W32_F (TxStatus0 + (entry * sizeof (u32)),
tp->tx_flag | max(len, (unsigned int)ETH_ZLEN));
This code is executed after some data has been written into a buffer to be handed over to a DMA engine. The wmb() ensures that the write into the buffer is committed before the write that initiates the DMA transaction, removing a risk for data corruption. Since only the ordering between these two specific accesses is necessary, and they are both writes, a wmb() is the correct choice. Note that this barrier is also SMP safe, as its description is a superset of the smp_wmb() functionality.
Another example from linux/drivers/net/bnx2.c:
/* Memory barrier necessary as speculative reads of the rx
* buffer can be ahead of the index in the status block
*/
rmb();
while (sw_cons != hw_cons) {
As described by the comment, in this situation the primary purpose of the barrier is to prevent the processor (as well as the compiler) from performing read accesses described within the while loop before that control block is actually entered.
Linux Kernel 패치 가이드라인을 보면 "모든 메모리 배리어(barrier(), rmb(), wmb())는 소스코드에 그것들이 무엇을 하고 왜 필요한지에 대해 주석을 작성해야 한다."고 언급하고 있다.
비록 철저히 지켜지고 있지는 못하지만, 이것은 커널 코드 자체가 barrier 의 유용한 레퍼런스가 될 수 있다는 것을 의미한다.
예를 들면, linux/drivers/net/8139too.c 소스로부터 가져온 다음을 보라.
/*
* Writing to TxStatus triggers a DMA transfer of the data
* copied to tp->tx_buf[entry] above. Use a memory barrier
* to make sure that the device sees the updated data.
*/
wmb();
RTL_W32_F (TxStatus0 + (entry * sizeof (u32)),
tp->tx_flag | max(len, (unsigned int)ETH_ZLEN));
이 코드는 DMA 엔진으로 일부 데이터를 넘겨주기 위해 buffer 에 쓰여진 후에 실행된다. wmb() 는 buffer 에 쓰여진 데이터가 DMA 트랜잭션의 initiate write 이전에 커밋되는 것을 보장한다.
데이터 corruption 에 대한 위험을 없애는 것이다. 이 두 특정 접근들 사이의 ordering 이 필요하고 그 두 접근이 모두 쓰기이기 때문에, wmb() 가 올바른 선택이 된다.
이 barrier 가 SMP 환경에서도 역시 안전하다는 것을 기억하라. 왜냐하면, wmb() 는 smp_wmb()의 superset 이니까.
linux/drivers/net/bnx2.c 로부터 가져온 또 다른 소스를 보자.
/* Memory barrier necessary as speculative reads of the rx
* buffer can be ahead of the index in the status block
*/
rmb();
while (sw_cons != hw_cons) {
주석에 설명되어 있듯이, 이 경우에 barrier 의 주 목적은 프로세서(컴파일러도 마찬가지)가 control block 으로 진입하기 전에 while 루프내의 읽기 접근을 수행하는 것을 막기 위한 것이다.
Cost of barriers
The very reason for using barriers is to prevent our tools and hardware from performing unsafe optimizations. Also, the different types of barriers exist in order to describe exactly which memory ordering you need to enforce. This means that starting to insert barriers everywhere, or to use mb() wherever a barrier is needed, can have a negative impact on your software performance. It can be well worth spending the extra time to figure out whether you actually need a barrier in a specific situation, and if so which specific barrier it should be.
barrier 를 사용하는 이유는 우리의 툴과 하드웨어가 안전하지 않은 최적화를 수행하는 것을 막기 위한 것이다.
또한, 정확히 어떤 메모리 ordering 이 필요한지에 따라 적절한 것을 사용하기 위해 다른 종류의 barrier 들이 존재한다. 이는 여기저기 barrier 집어넣거나 barrier 가 필요한 곳마다 mb()를 사용하는 것이 여러분의 소프트웨어 성능에 악영향을 줄 수 있다는 것을 의미한다.
특정 상황에서 barrier 가 정말 필요한지와 필요하다면 어떤 barrier 가 필요한지에 대해 시간을 투자할 가치가 충분히 있다.
%% volatile 키워드에 대해 댓글에 언급하였다.

공부를 하다보니 한가지 주의할 점이 있다.
컴파일러가 최적화를 수행할 때 컴파일러 barrier 를 넘나들도록 명령어 재배치를 하지 못하는 것으로 언급이 되긴 했지만, 사실 메모리와 관련이 없는 코드라면 barrier 를 넘나들면서 최적화를 해도 문제가 되지 않을 것이다.
실제로도 컴파일러는 이런 경우 컴파일러 barrier 를 넘나들도록 최적화를 수행할 수 있다.
http://studyfoss.egloos.com/5128961
위의 다양한 barrier 들과 항상 비교되거나 혼동되는 것이 있는데 volatile 변수가 그렇다.
때로는, volatile 이라는 키워드를 사용하면 마치 이것이 메모리 barrier 인 것처럼 착각하는 사람도 있는 것 같다.
C/C++가 정의하는 volatile 키워드는 이 값이 언제든지 변할 수 있기에 컴파일러는 최적화하지 말 것을 지시한다.
이 말을 좀더 구체적으로 얘기하면, 컴파일러가 최적화할 때는 변수가 가능하다면 최대한 CPU 레지스터에 머물게 하여 성능을 극대화할 수 있도록 하는데, volatile 을 사용하면 이를 메모리에서 읽어오도록 만든다.
하지만, 이 메모리라는 것이 반드시 물리 메모리를 의미하는 것은 아닐 수 있다. 왜냐하면, CPU 입장에서는 캐시가 곧 메모리인 까닭이다.
아래의 설명이 volatile 에 대해 가장 명확하게 설명하는 글이 아닌가 한다.
1. volatile 키워드가 붙은 variable들에 대해서 컴파일러는 register allocation을 하지 않을 것이므로, 해당 변수들이 레퍼런스될 때마다 매번 LDR/STR (ARM에서) 혹은 MOV (X86에서) 가 불리게 될 것이지만,,, volatile은 어디까지나 컴파일러 수준에서의 노력에 불과할 뿐이고,
2. 실제로 그 메모리가 (ARM의) data cache 혹은 (X86따위의) L1/L2 cache에 캐시될 것인지는 하드웨어 셋팅에 달린 문제인지라, 코드에 달랑 volatile 적어놓는 걸로는 부족하고 (ARM의 경우) MMU 셋팅에서 해당 physical address space가 non-bufferable 및 non-cachable 으로 맞춰져 있어야 되겠지요.
개인적으로 한국 사이트 중에서는 이곳이 volatile 관련해서 가장 읽을만한 내용이 있는 곳인 것 같다.
공부를 하다보니 한가지 주의할 점이 있다.
컴파일러가 최적화를 수행할 때 컴파일러 barrier 를 넘나들도록 명령어 재배치를 하지 못하는 것으로 언급이 되긴 했지만, 사실 메모리와 관련이 없는 코드라면 barrier 를 넘나들면서 최적화를 해도 문제가 되지 않을 것이다.
실제로도 컴파일러는 이런 경우 컴파일러 barrier 를 넘나들도록 최적화를 수행할 수 있다.
http://studyfoss.egloos.com/5128961
위의 다양한 barrier 들과 항상 비교되거나 혼동되는 것이 있는데 volatile 변수가 그렇다.
때로는, volatile 이라는 키워드를 사용하면 마치 이것이 메모리 barrier 인 것처럼 착각하는 사람도 있는 것 같다.
C/C++가 정의하는 volatile 키워드는 이 값이 언제든지 변할 수 있기에 컴파일러는 최적화하지 말 것을 지시한다.
이 말을 좀더 구체적으로 얘기하면, 컴파일러가 최적화할 때는 변수가 가능하다면 최대한 CPU 레지스터에 머물게 하여 성능을 극대화할 수 있도록 하는데, volatile 을 사용하면 이를 메모리에서 읽어오도록 만든다.
하지만, 이 메모리라는 것이 반드시 물리 메모리를 의미하는 것은 아닐 수 있다. 왜냐하면, CPU 입장에서는 캐시가 곧 메모리인 까닭이다.
아래의 설명이 volatile 에 대해 가장 명확하게 설명하는 글이 아닌가 한다.
1. volatile 키워드가 붙은 variable들에 대해서 컴파일러는 register allocation을 하지 않을 것이므로, 해당 변수들이 레퍼런스될 때마다 매번 LDR/STR (ARM에서) 혹은 MOV (X86에서) 가 불리게 될 것이지만,,, volatile은 어디까지나 컴파일러 수준에서의 노력에 불과할 뿐이고,
2. 실제로 그 메모리가 (ARM의) data cache 혹은 (X86따위의) L1/L2 cache에 캐시될 것인지는 하드웨어 셋팅에 달린 문제인지라, 코드에 달랑 volatile 적어놓는 걸로는 부족하고 (ARM의 경우) MMU 셋팅에서 해당 physical address space가 non-bufferable 및 non-cachable 으로 맞춰져 있어야 되겠지요.
개인적으로 한국 사이트 중에서는 이곳이 volatile 관련해서 가장 읽을만한 내용이 있는 곳인 것 같다.