
포인터(pointer)와 문자배열(Char Array), 문자열상수(String Constant)의 관계
여러분은 아래 두줄 선언의 차이를 정확하게 알고 계시나요 ?
- char * p = "abcd"; --- (1)
- char n[] = "abcd"; --- (2)
위 두 라인의 차이점에 대해 저도 종종 혼동하기도 하고 정확하고 Detail 하게 설명할 수 없었던 적도 있습니다.
사실 짧은 지식으로 간단히 얘기하면 할말이 많지 않지만, 깊숙하게 파고들기 시작하면 위의 두 라인을 가지고도 강의 한시간은 채울 수 있을 것입니다.
위의 첫번째 라인에서 p 는 문자열상수 "abcd" 를 가리키는 stack 포인터 변수이고, 두번째 라인에서 n 은 "abcd"라는 문자열이 저장된 stack 영역을 대표하는 stack array 이름, 즉 포인터 상수를 나타냅니다.
포인터 변수는 말 그대로 포인터이므로 p = "xyz" 와 같이 다른 문자열 상수를 가리키도록 변경할 수 있지만, 포인터 상수는 변경불가한 고정된 주소값을 가지기 때문에 n = "xyz" 와 같이 변경할 수 없습니다.
(1) 번에서 p 자체는 stack 에 잡히는 포인터 변수입니다. 그리고, "abcd"는 컴파일러에서 컴파일 시에 실행파일 또는 so library 에 써놓는 문자열상수, 즉 고정된 문자열입니다.
컴파일러는 컴파일 시에 상수들을 모두 모아서 실행파일 또는 so library 의 특정 부분에 써놓습니다.
그리고, 실행파일을 로드 시 이러한 상수들을 프로그램의 data 영역 중 읽기 전용 static 메모리 공간에 올려놓습니다.
올려 놓은 후 위의 코드를 실행 시 stack 변수 p 가 할당되고, 해당 p 변수에 읽기 전용 메모리 공간에 저장된 문자열상수의 주소값을 할당하는 것이죠.
"abcd" 문자열이 저장될 만큼의 stack 영역을 할당하고 곧 바로 초기화를 한번에 수행해주기 위한 구문입니다.
마치 의미상으로만 따지면 아래의 두 줄을 한번에 수행하는 것이라고 할까요 ?
char n[4]; strcpy(n, "abcd");
int main()
{
char n[] = "abcd";
n[0] = 'n';
printf("[%s]n", n);
}
위의 소스는 문자열 array 를 가리키는 n 을 이용하여 첫번째 문자를 변경해본 것입니다.
아래의 결과처럼 변경이 아주 잘되는군요.
sh> ./a.out [nbcd]
그렇다면, 아래의 결과는 어떨까요 ?
int main()
{
char * p = "abcd";
p[0] = 'p';
printf("[%s]n", p);
}
실행해보면 세그멘테이션 오류 (Segmentation Fault)가 발생합니다.
읽기 전용 문자열상수가 저장된 영역에 포인터 변수 p 를 이용하여 접근하여 값을 수정하려고 했기 때문입니다.
gdb 를 사용해서 차이점을 좀더 살펴볼까요 ?
아래는 포인터 변수 p 를 사용하는 소스를 -g 옵션으로 컴파일한 다음 gdb 로 수행해본 것입니다.
(gdb) b main Breakpoint 1 at 0x4004fc: file t.c, line 3. (gdb) r Starting program: /home/dplee/tmp/a.out Breakpoint 1, main () at t.c:3 3 char * p = "abcd"; (gdb) p p $1 = 0x0 (gdb) n 5 p[0] = 'p'; (gdb) print p $2 = 0x40061c "abcd" # 주소와 주소가 가리키는 공간에 저장된 값이 같이 보임. (gdb) p p[0] $3 = 97 'a' (gdb) x/4c 0x40061c 0x40061c:97 'a'98 'b'99 'c'100 'd' (gdb) n Program received signal SIGSEGV, Segmentation fault. 0x0000000000400508 in main () at t.c:5 5 p[0] = 'p';
위의 comment 를 보면 p 라는 변수를 print 해본 결과 주소와 값을 같이 보여줌을 알 수 있습니다.
그러면, array 이름인 n 일 경우에 어떤지 비교해보죠.
(gdb) b main
Breakpoint 1 at 0x40056c: file t.c, line 2.
(gdb) r
Starting program: /home/dplee/tmp/a.out
Breakpoint 1, main () at t.c:2
2{
(gdb) n
3 char n[] = "abcd";
(gdb) n
5 n[0] = 'n';
(gdb) print n
$1 = "abcd" # 주소는 나오지 않고 문자열 자체만 나온다.
주소는 안나오고 문자열만 나오는군요. 당연합니다. n 이라는 것은 포인터변수가 아니기 때문이죠.
Array 공간에 저장된 값들이 "abcd" 이니 그냥 그 값들을 보여줄 뿐 포인터가 아니니 주소값이 나오지 않는 것입니다.
p 와 n 은 둘다 p[i], n[i] 과 같이 문자열 중 각각의 문자 character 를 index 를 이용하여 접근할 수 있습니다.
하지만, 이를 이용하여 변경을 할수 있냐없냐의 차이가 있습니다.
이번에는 objdump 라는 tool 을 사용하여 컴파일 후 만들어지는 object file 을 Disassemble 하여 위의 내용을 확인하는 차원에서 간단히 분석해 보겠습니다.
int main()
{
char * p = "abcd";
}
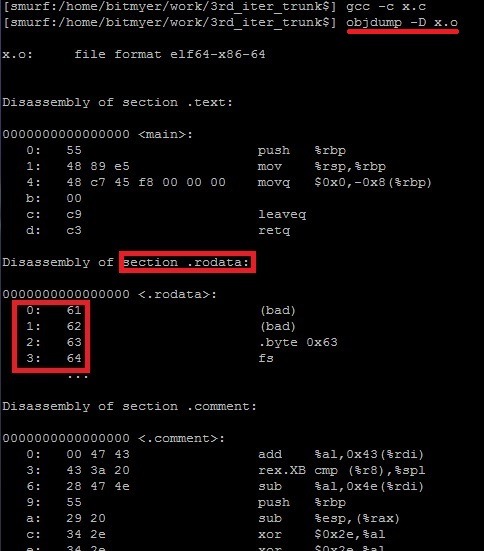
위의 코드를 x.c 로 저장한 후 컴파일하여 objdump -D x.o 명령을 수행하면 다음과 같은 결과를 볼 수 있습니다.
결과를 보면 object binary 의 내용을 section 별로 잘 분류하여 보여주는 것을 알 수 있습니다.
"abcd" 는 각각 ascii code 로 변환하면 0x61, 0x62, 0x63, 0x64 입니다.
이를 통해 확인해보니 해당 문자열이 rodata (Read-Only Data) 영역에 저장되어 있는 것을 확인할 수 있습니다.
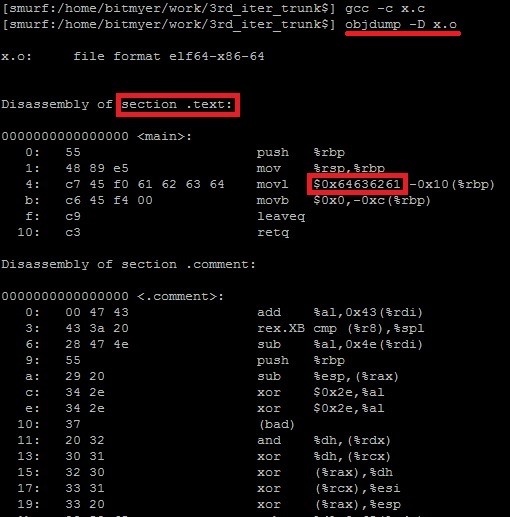
그렇다면, 아래와 같이 array 초기화를 수행하는 코드에 대해서는 어떤 결과가 나오는지 볼까요 ?
int main()
{
char p[] = "abcd";
}
아래 결과를 보니 rodata section 에 대한 내용은 사라지고 text section, 즉 코드 영역에 0x64636261 값을 직접 할당하는 것을 볼 수 있네요.
즉, 위의 코드에서 "abcd" 의 값은 읽기 전용 메모리 공간에 있는 것이 아니라 실행 시에 직접 초기화로 사용하는 코드 영역 상의 rvalue 값일 뿐이네요.
어때요 ? 이제 차이점들이 확실히 보이나요 ? ^^
여러분에게 보여드릴 글을 쓰면서 저 또한 흐지부지 흩어져있던 개념들을 머리속에 잘 정리할 수 있는 계기가 되는 것 같아서 좋습니다. ^^;;;
그럼~

감사합니다
찾아주셔서 제가 감사드립니다. ^^
열심히 공부합시다~
와…. 유닉스 C 프로그래밍 하면서 제일 헷갈리던 건데 감사합니다 ㅎㅎ
저도 기본적인 C 문법조차 다른걸 공부하다보면 까먹습니다. ㅎㅎ
원리를 알면 기억이 오래가고 까먹더라도 다시 되새기기가 쉽겠죠. ^^
감사합니다.
안녕하세요, 강좌 잘 보고 있습니다. ^^
프로그래밍이랑은 거리가 멀어서 간단한것도 아직은 어렵게 느껴지긴하는데요~ 하나씩 설명해주신거 잘 보고 있습니다. 감사합니다~
아… 강좌를 잘 써나갈 자신은 있는데 게으름이… ㅠㅜ
열심히 공부하셔서 몇년 후에는 저 좀 가르쳐주세요~ 히~~ ^^;;
화이링~
와…. 유닉스 C 프로그래밍 하면서 제일 헷갈리던 건데 감사합니다 ㅎㅎ
저도 기본적인 C 문법조차 다른걸 공부하다보면 까먹습니다. ㅎㅎ
원리를 알면 기억이 오래가고 까먹더라도 다시 되새기기가 쉽겠죠. ^^
감사합니다.
안녕하세요, 강좌 잘 보고 있습니다. ^^
프로그래밍이랑은 거리가 멀어서 간단한것도 아직은 어렵게 느껴지긴하는데요~ 하나씩 설명해주신거 잘 보고 있습니다. 감사합니다~
아… 강좌를 잘 써나갈 자신은 있는데 게으름이… ㅠㅜ
열심히 공부하셔서 몇년 후에는 저 좀 가르쳐주세요~ 히~~ ^^;;
화이링~
감사합니다
찾아주셔서 제가 감사드립니다. ^^
열심히 공부합시다~