
Memory Access Ordering(1) – Introduction
The original(원문) : memory-access-ordering--an-introduction Posted by ARM Lief
메모리에 대한 접근이 순차적 실행 모델(Sequential Execution Mode)에서만 이루어진다면 얼마나 머리가 덜 아프겠는가 ? 하지만, 메모리 접근에 대한 Ordering 이 개발자가 알지 못하는 사이 컴파일러나 프로세서의 다양한 최적화 기법(Out-of-order execution, 예측적 실행 등)에 의해 전혀 다른 방향으로 수행이 될 수 있다. 이러한 메모리 접근의 Ordering 에 변화를 주는 요소들이 무엇이고 어떠한 변화들이 있는지에 대한 좋은 소개 자료라고 생각한다.
이해하기에 모호한 번역이 있는 경우 바로 원문을 볼 수 있도록 원문과 번역 내용의 순서로 배치하였다.
I recently gave a presentation at the Embedded Linux Conference Europe 2010 called Software implications of high-performance memory systems. This title was my sneaky (and fairly successful) way to get people to attend a presentation really about memory access (re)ordering and barriers. I would now like to follow that up with a few posts on the topic. In this post, I will be introducing a few concepts and explain the reasons behind them. In future posts, I will follow up with some practical examples.
나는 최근에 Embedded Linux Conference Europe 2010 에서 "Software implications of high-performance memory systems"라는 제목으로 프리젠테이션을 했다. 이 제목이 내게는 사람들로 하여금 memory access ordering 과 barrier 에 관심을 갖게 하는 간사하지만 효과가 좋은 방법이다.
이제 그 주제에 대해 몇개의 포스팅으로 더 얘기를 해보고자 한다. 이 포스팅에서 나는 몇몇 개념과 그 뒤에 숨은 배경들에 대해 설명할 것이다. 몇몇의 실제 예제들도 다루겠다.
The Sequential Execution Model (순차적 실행 모델)
In the Good Old Days, computer programs behaved in practice pretty much the way you might instinctively expect them to from looking at the source code:
- Things happened in the way specified in the program.
- Things happened in the order specified in the program.
- Things happened the number of times specified in the program (no more, no less).
- Things happened one at a time.
In modern computer architecture, this nostalgic fantasy is sometimes referred to as the Sequential Execution Model. In order for existing programs and programming models to remain functional, even the most extreme modern processors will attempt to preserve the illusion of Sequential Execution from within the executing program. However, underneath your feet a lot of things will be going on that cannot be hidden from outside the processor.
예전 좋은 시절에는, 컴퓨터 프로그램이 소스코드를 직관적으로 해석한대로 거의 동작했다.
- 모든 것이 프로그램에 명시된대로 돌아갔다.
- 모든 것이 프로그램에 명시된 순서대로 돌아갔다.
- 모든 것이 프로그램에 명시된 횟수대로 돌아갔다. (더도 덜도 아니다.)
- 모든 것이 한순간에 하나만 발생했다.
현대 컴퓨터 아키텍쳐에서는, 이런 천국의 환타지가 때때로 Sequential Execution Model 이라고 불린다.
Reality
The reality, however, is that in order to improve performance (both with regards to speed and power) a lot of optimizations are being performed at many different levels of your system.
그러나, 성능을 개선하기 위해 많은 최적화가 여러분 시스템의 많은 Level 에서 이루어지는 것이 현실이다.
Optimizing Compilers
An optimizing compiler can heavily refactor your code in order to hide pipeline latencies or take advantage of microarchitectural optimizations. It can decide to move a memory access earlier in order to give it more time to complete before the value is required, or later in order to balance out the accesses through the program. In a heavily-pipelined processor, the compiler might in fact rearrange all kinds of instructions in order for the results of previous instructions to be available when their results are required.
최적화를 수행하는 컴파일러는 파이프라인 지연을 숨기기 위해, 또는 microarchitectural 최적화를 이용하기 위해 당신의 코드를 대량으로 변경시킨다. 값을 필요로 하기 전에 시간을 더 주기 위해 미리 메모리 접근을 하도록 할 수도 있고, 혹은 프로그램 흐름상 균형을 위해 메모리 접근을 뒤로 미룰 수도 있다. heavily-pipelined 프로세서에서는, 컴파일러는 명령어의 결과들이 require 될 때 이전의 명령들의 결과가 available 하도록 모든 종류의 명령들을 재배치할 것이다.
A classic example which is commonly used to explain the problem is the following:
int flag = BUSY;
int data = 0;
int somefunc(void)
{
while (flag != DONE);
return data;
}
void otherfunc(void)
{
data = 42;
flag = DONE;
}
Assume the above code runs in two separate threads, with thread A calling otherfunc() to update a value and indicate a completed operation and thread B calling somefunc() to wait until the signal of completion arrives before returning the value of variable data. There is nothing in the C language specification that guarantees that somefunc() will not generate code that reads data before it begins polling the value of flag. This means that it is perfectly legal for somefunc() to return either 0 or 42. While there are some possibilities to work around this for the code generation, this would still do nothing to prevent reordering done in hardware (see below).
이러한 문제를 설명하기 위해 주로 사용되는 전통적인 예는 아래와 같다.
int flag = BUSY;
int data = 0;
int somefunc(void)
{
while (flag != DONE);
return data;
}
void otherfunc(void)
{
data = 42;
flag = DONE;
}
위의 코드가 두개의 스레드들에 의해 수행된다고 가정해보자.
스레드 A 는 연산의 완료를 알려주기 위한 값을 갱신하기 위해 otherfunc()을 호출하고, 스레드 B는 somefunc() 함수를 호출하여 data 변수의 값을 return 되기 전에 연산의 완료가 도착하는 신호를 포착할 때까지 기다린다.
C 언어의 스펙에는 somefunc() 함수가 flag 값에 대한 polling 을 시작하기 전에 data 를 읽도록 코드를 작성하지 않는다는 어떤 내용도 없다.
이것은 곧 somefunc() 함수가 0 이든 32 이든 어떤 것을 리턴해도 완전히 합법적이라는 말이다.
코드를 생성할 때는 이에 대한 해결책이 있는 반면, 여전히 하드웨어에 의한 reordering 은 막을 길이 없다. (아래를 보자.)
Multi-issuing
Many modern processors support issuing (and executing) multiple instructions every clock cycle. Even if you explicitly placed an assembly instruction after another, they can end up being issued and executed in parallel.
Imagine the following instruction sequence in ARM assembly:
Cycle Issue
0 add r0, r0, #1
1 mul r2, r2, r3
2 ldr r1, [r0]
3 mov r4, r2
4 sub r1, r2, r5
5 str r1, [r0]
6 bx lr
On a dual-issuing processor, this sequence might actually execute as this:
Cycle Issue0 Issue1
0 add r0, r0, #1 mul r2, r2, r3
1 ldr r1, [r0] mov r4, r2
2 sub r1, r2, r5 *stall*
3 str r1, [r0] bx lr
In this example, nothing is issued by Issue1 in cycle 2, since the subsequent instruction requires the result from the sub that is issued into Issue0. This instruction is instead issued in cycle 3 – in parallel with the subroutine return.
현대의 프로세서들은 각 clock cycle 마다 다수의 명령어들을 실행(issuing, executing)하도록 지원한다. 설사 당신이 하나의 어셈블리 명령을 다른 명령의 뒤에 명시적으로 배치를 했더라도, 그 명령들은 동시에 issue & execue 될 수 있다.
ARM 어셈블리에서 다음과 같은 명령어 순서를 생각해보자.
Cycle Issue
0 add r0, r0, #1
1 mul r2, r2, r3
2 ldr r1, [r0]
3 mov r4, r2
4 sub r1, r2, r5
5 str r1, [r0]
6 bx lr
dual-issuing 프로세서에서, 이러한 순서는 실제적으로는 다음과 같이 실행될 것이다.
Cycle Issue0 Issue1
0 add r0, r0, #1 mul r2, r2, r3
1 ldr r1, [r0] mov r4, r2
2 sub r1, r2, r5 *stall*
3 str r1, [r0] bx lr
이러한 예에서, Issue1 에 의해서 cycle2 에서는 아무 것도 issue 되지 않았다.
왜냐하면, 그 다음의 명령어가 Issue0 에 의한 sub 명령어의 결과를 필요로 하기 때문이다.
대신 이 명령어는 cycle3 에서 함수 리턴과 함께 issue 된다.
Out-of-order execution
The first ARM processor to support out-of-order execution was the ARM1136J(F)-S™, which permitted non-dependent load and store operations to complete out of order with each other. In practise, this means that a data access that misses in the cache can be overtaken by other data accesses that hit (or miss) in the cache, as long as there are no data dependencies between them. It also permitted load-store instructions to complete out-of-order with data processing instructions where there were no data dependencies (for example where a load provided the address for a subsequent load or store).
Fast-forward a few years to the Cortex™-A9. This processor supports out-of-order execution of most non-dependent instructions in many situations. When an instruction stalls because it is waiting for the result of a preceding instruction, the core can continue executing subsequent instructions that do not need to wait for the unmet dependencies.
Consider the following code-snippet, which has a couple of instructions that could potentially take more than one cycle before the result is available to subsequent instructions. Both a mul and a ldr can on several architectures require multiple cycles before their results are available. In this case we assume 2 cycles for each.
add r0, r0, #4
mul r2, r2, r3
str r2, [r0]
ldr r4, [r1]
sub r1, r4, r2
bx lr
If we execute this code on an in-order processor, the execution will look something like the following:
Cycle Issue
0 add r0, r0, #4
1 mul r2, r2, r3
2 *stall*
3 str r2, [r0]
4 ldr r4, [r1]
5 *stall*
6 sub r1, r4, r2
7 bx lr
While if we execute it on an out-of-order processor, we might see something more like:
Cycle Issue
0 add r0, r0, #4
1 mul r2, r2, r3
2 ldr r4, [r1]
3 str r2, [r0]
4 sub r1, r4, r2
5 bx lr
By permitting the ldr to execute while we wait for the mul to complete so that the str can progress, we have also given more time for the ldr to complete before its value is needed.
비순차적 명령어처리(out-of-order executio)를 지원한 첫번째 ARM 프로세서는 ARM1136J(F)-STM 이다.
이 프로세서는 독립적인 load 와 store 연산이 서로 비순차적으로 실행하는 것을 허용하였다. 이것은 cache miss 를 발생시킨 data access 가 데이터 의존성만 서로 없다면 다른 data access 에 의해 추월당할 수 있다는 것을 의미한다. 이 프로세서는 또한 load-store 명령어들이 의존성이 없는 데이터 처리 명령어들과 함께 비순차적으로 완료하도록 허용하였다. (예를 들면, load 가 그 다음의 load 나 store 를 위한 주소를 제공하는 그런 데이터 처리 명령어들말이다.)
몇년이 지나 CortexTM-A9 가 나왔다.
이 프로세서는 많은 상황에서 대부문의 의존성이 없는 명령어들이 비순차적으로 실행되는 것을 지원한다.
하나의 명령이 앞선 명령의 결과를 기다리고 있어서 stall 상태인 경우, 코어는 기다릴 필요가 없는 다음 명령을 계속해서 실행한다.
다음 코드 조각을 보자.
이는 실행의 결과가 다음 명령들에게 유효하기 전에 하나 이상의 cycle 을 소모할 수 있는 몇개의 명령어들을 가지고 있다. mul 과 ldr 은 둘다 몇몇의 아키텍쳐에서는 결과가 유효하기까지 다수의 cpu cycle 을 필요로한다.
이 예에서는 2 cycle 이 필요하다고 가정해보자.
add r0, r0, #4
mul r2, r2, r3
str r2, [r0]
ldr r4, [r1]
sub r1, r4, r2
bx lr
이코드를 순차적 프로세서에서 실행한다면, 아래와 유사하게 실행될 것이다.
Cycle Issue
0 add r0, r0, #4
1 mul r2, r2, r3
2 *stall*
3 str r2, [r0]
4 ldr r4, [r1]
5 *stall*
6 sub r1, r4, r2
7 bx lr
반면에 비순차적(out-of-order) 프로세서에서 실행한다면, 아래와 유사하게 실행될 것이다.
Cycle Issue
0 add r0, r0, #4
1 mul r2, r2, r3
2 ldr r4, [r1]
3 str r2, [r0]
4 sub r1, r4, r2
5 bx lr
ldr 명령이 mul 명령을 기다리는 동안 실행하도록 허용하여 str 명령이 진행될 수 있도록 한다.
이렇게 해서 ldr 명령에게도 완료할 시간을 더 벌어준 셈이다.
Speculation
Speculation can be described simply as the core executing, or beginning to execute, an instruction before it knows whether that particular instruction should be executed or not. This means that the result will be available sooner if conditions resolve such that the speculation was correct. Examples of this would be when the code makes use of general-purpose conditional execution in either the ARM or Thumb instruction sets, or when the core encounters a conditional branch instruction. The core can then speculatively execute the conditional instruction, or instructions following the conditional branch instruction. If it does so, it must ensure that any signs of it doing this are erased if the speculation turns out to have been incorrect.
Where memory load instructions are concerned, speculation can go a bit further. A load from a cacheable location can be speculatively issued, and this can in turn lead to that location being copied in from external memory, potentially evicting an existing cache line. Many modern processors go one step further and monitor data accesses performed in order to detect patterns, and bring subsequent addresses in that pattern into the cache even before the instruction enters the processor pipeline.
예측(Speculation)은 특정 명령을 실행해도 되는지 아닌지를 미리 알고 실행을 시작하는 것이라고 단순히 설명될 수 있다. 이는 이러한 예측이 정확(correct)하도록 조건들이 마련된다면 예측에 의한 실행으로 인해 결과를 빠르게 획득하여 사용할 수 있다는 것을 의미한다.
ARM 이나 Thumb 명령어셋에서 일반적인 목적의 조건명령을 사용할때, 또는 코어가 조건 branch 명령을 만났을 때가 그 예이다. 코어는 이때 미리 예측(speculatively)하여 조건 명령 또는 조건분기(conditional branch)명령 뒤를 따르는 명령들을 실행한다. 그렇게 하면, 코어는 만약 예측이 어긋났을 때 이것들을 모두 원상복귀시키는 것을 보장해야 한다.
메모리 load 명령을 고려할 때는 예측은 어느정도 더 앞서나갈 수 있다.
캐싱이 가능한 위치로부터의 load 는 speculatively issued 되어, 이것이 순차적으로 외부 메모리로부터의 복사를 야기시킨다. 또한, 현재의 캐시라인의 내용을 evict 시키고 말이다.
현대의 프로세서들은 한발짝 더 나아가서, 패턴을 파악하기 위해 순차적으로 실행되는 데이터 접근들을 모니터링하여, 명령어가 프로세서의 파이프라인으로 진입하기도 전에 패턴내의 연속된 주소들을 캐쉬로 읽어들인다.
Load-Store Optimizations
External memory accesses in a high-performance system tend to have significant latencies – even if the core:memory clock ratio is as good as 2:1, the actual data transfer can only take place after many cycles of setup times. This can be anywhere between 5–50 bus clock cycles, depending mainly on the power profile of the system – with caches or bridges on the way adding additional cycles on top of this. With a less favorable core-to-memory clock ratio, this effect is multiplied.
In order to reduce the effect of these latencies, processors very much attempt to optimize their memory accesses to (if possible) reduce the number of transactions by writing more data with each transaction – using bursts to transfer longer streams of data with only the latencies of a single transaction. This can for example mean that multiple writes to buffered memory can be merged together into one transaction.
고성능 시스템에서 외부 메모리에 대한 접근은 심각한 latency 하락을 유발하는 경향이 있다. - 코어:메모리의 클럭비가 2:1 일때조차도, 실제 데이터의 전송은 setup 시간에서 많은 cycle 을 소요한다.
이는 5-50 버스 컬럭 사이클정도 소모되는데, 이 시간은 시스템의 power profile 에 의해 주로 좌우된다.
캐쉬와 브리지에 의해 추가적으로 더 많은 cycle 이 필요하다.
코드:메모리 클럭비가 더 좋다면 효과는 곱절이 될 것이다.
이러한 latency 영향을 감소시키기 위해, 프로세서는 가능하다면 메모리 접근을 할 때 한 트랜잭션에 더 많은 데이터를 쓸 수 있도록 하여 트랜잭션의 수를 감소시킬 수 있도록 최적화를 수행한다.
이는 곧 buffered memory 에 대한 복수의 쓰기 연산이 하나의 트랜잭션으로 통합되어 수행될 수 있다는 것을 의미한다.
Cache Coherent Multi-Core
When using a multi-core processor, hardware-based cache coherency management can cause cache lines to migrate transparently between cores. This can potentially cause different cores to see updates to cached memory locations in different order.
To give a concrete example of this: the example of somefunc() and otherfunc() above has another potential aspect when executing in a multi-core SMP system. If the two threads were executing on
separate cores, then the combination of hardware cache coherency management, speculation and out-of-order execution means that the order of memory accesses may be seen differently by the different cores.
Simply put, hardware cache coherency management means that cache lines can be moved across between the cores to be available wherever they are accessed. Since out-of-order capable processors can load one memory location from the cache while waiting for the result of another load (or store) to complete, it would be perfectly permissible for the core executing somefunc() to speculatively load the value of data before the value of flag actually changed to DONE - even if this was not the order in which the instructions were within the compiled application.
멀티코어 프로세서를 이용할 때, 하드웨어에 의한 캐쉬 데이터 일관성(cache coherency)관리는 코어사이에 캐쉬라인의 이동을 발생시킬 수 있다. 이것은 잠재적으로 서로 다른 코어들이 캐슁된 메모리에 대한 갱신을 서로 다른 순서로 볼 수 있도록 만들 수 있다.
이에 대한 구체적인 예를 들면, 위쪽의 somefunc() 과 otherfunc() 함수가 멀티코어 SMP 시스템에서 실행될 때는 또 다른 양상을 보일 수 있다는 것이다.
만약 두 개의 스레드가 각각 다른 코어에서 수행되고, 또한 하드웨어에 의한 캐쉬일관성 관리환경에서 수행된다면, 예측(speculation)과 비순차 실행이라는 것은 메모리 접근의 순서가 "다른 코어에게는 다르게 보일 수 있다"는 것을 의미한다.
간단히 말해서, 하드웨어에 의한 캐쉬 일관성 관리는 접근하는 코어들 사이에 캐쉬라인이 옮겨질 수 있다는 것을 의미한다. 비순차적 실행이 가능한 프로세서는 다른 load 나 store 의 결과를 기다리는 동안 캐쉬로부터 또 다른 load 를 수행할 수 있다. 따라서, flag 값이 DONE 으로 실제 변경되기 전에, somefunc() 함수를 실행하는 코어는 data 의 값을 예측적으로 load 하는 것이 완전히 허용된다.
비록, 이것이 컴파일된 application 내에 있는 명령의 순서 그대로가 아니라도 말이다.
External Memory Systems
The complexities continue even once you get out into the external memory system. To achieve high performance in a system with many bus masters (agents), the interconnect might be configured in a multi-layer system. This effectively means that different agents (or masters) can have different routes to the various devices (or slaves) in the system. Also, peripherals like memory controllers might have more than one slave interface, allowing multiple agents to access it simultaneously.
External Memory 시스템의 경우도 복잡하기는 마찬가지다.
많은 수의 버스 마스터(masters, agents)를 가진 시스템에서 고성능을 달성하기 위해, 서로간의 연결을 multi-layer 로 구성한다. 이는 서로 다른 버스마스터가 시스템의 다양한 device(slave)들을 서로 다른 경로를 통해 접근할 수 있다는 것을 의미한다. 또한, 메모리 컨트롤러와 같은 주변장치는 하나 이상의 slave interface 를 가질 수 있어서, 다수의 agent 가 메모리를 동시에 접근하는 것을 허용하게 된다.
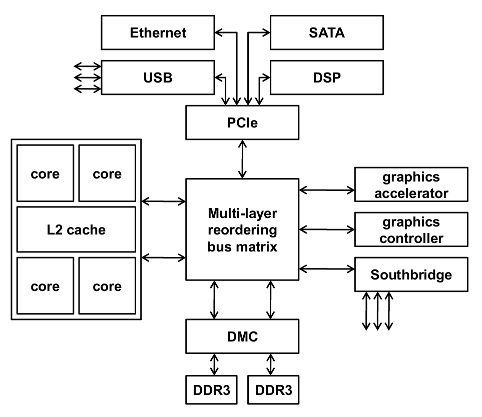
Conclusion
현대 컴퓨터 시스템에서는, 사람이 직관적으로 예측할 수 있는 것과는 다른 순서로 많은 것들이 수행될 수 있다.
그리고, 시스템의 agent 들 모두가 그 순서를 모두 받아들일 수 있는 것은 아니다.
다음 포스팅에서 나는 이것이 실제로 어떤 의미가 있고 여러분이 무엇을 알아야하는지에 대해 이야기할 것이다.
